Longitudinal interview outcome data reduction: Latent Class and Sequence analyses
Frauke Kreuter once commented on a presentation I gave that I should really be looking at sequence analysis for studying attrition in panel surveys. She had written an article on the topic with Ulrich Kohler ( here ) in 2009, and as of late there are more people exploring the technique (e.g. Mark Hanly at Bristol, and Gabi Durrant at Southampton ).
I am working on a project on attrition in the British Household Panel, and linking attrition errors to measurement errors. Attrition data can be messy. Below, you see the response outcome sequences of every initial panel member in the British Household Panel Survey. This figure obscures the fact individual respondents may frequently switch states (e.g. interview - noncontact - interview - refusal - not issued).
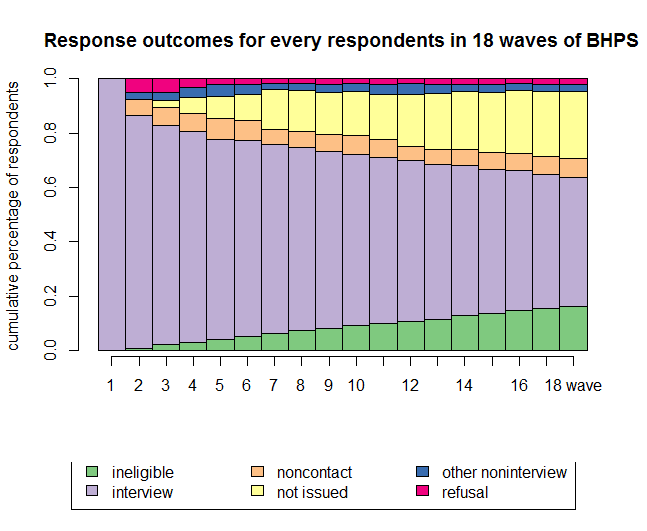
Figure 1: relative sizes of final interview outcomes at 18 waves of BHPS of wave 1 respondents
Although descriptive visualizations like these are informative, sequence analysis becomes analytically interesting when you try to “do” something with the sequences of information. In my case, I want to group all sequence chains into “clusters” or “classes” of people who have a similar process of attrition. Stata and R TraMineR offer possibilities for doing this. Both packages enable you to match sequences by optimal matching , so that for every sequence from every person you get a distance measure to every other sequence (person). In turn, this (huge) dustance matrix can then be used to classify all the sequences of all respondents into clusters. R offers a nice way to handle huge data matrices, by using aggregation and weighting by the way. See the WeightedCluster library.
Below, you find the results of the sequence analysis. The nice thing is that I end up with 6 clusters that look the same as the Classes that I got out of a Latent Class Analysis over summer. So now I feel much more confident using this classification.
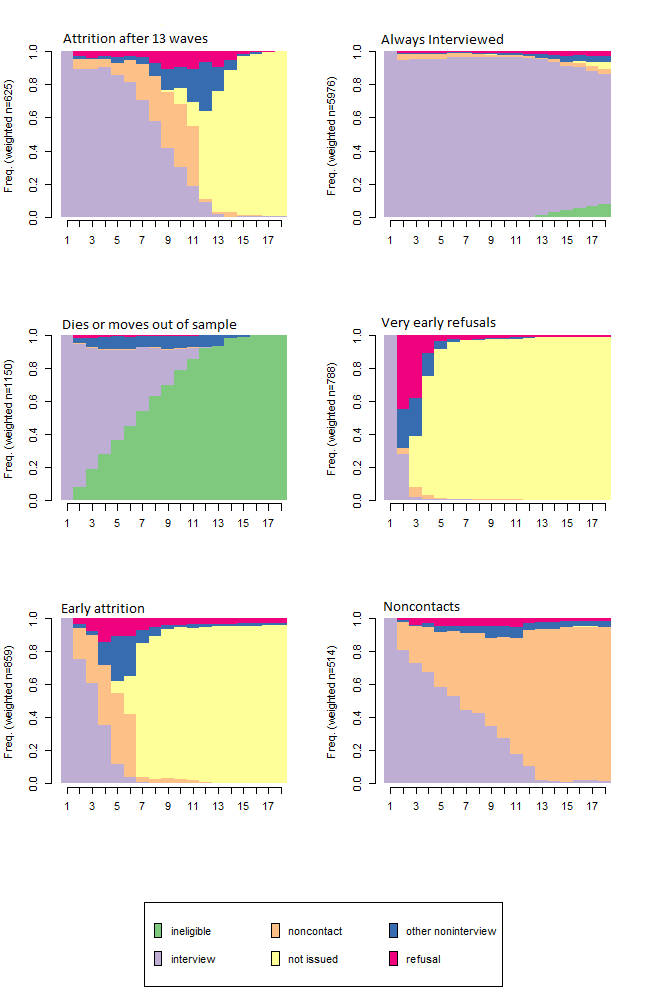
Figure 2: 6-cluster solution for sequence analysis on BHPS attrition patterns
The differences between sequence analysis and LCA are really minimal, and probably result from the fact that the Optimal Matching algorithm used in sequence analysis is more flexible (in that it would allow deletion, additions, substitutions etc to match), than Latent Class Analysis. But in practice, for my analyses, it doesn’t matter what technique I use. My results are equivalent. Personally, I like Latent Class analysis more, because it offers the option of linking the Latent Classes of attrition to substantive research data in one model.
Attrition data bear a resemblence to contact data recorded in a telephone or face-to-face survey. Interviewers make call or interview attempts, that bear a lot of information about the survey proecess, and could improve fieldwork, and reduce nonresponse and costs. I am imagining a paper where one links contact data at every wave, and combines that with attrition analyses, in a series of linked-sequence data analysis. That way, you can learn how specific sequences of call and contact data, lead to specific sequences of interview outcomes at later stages of the panel survey. It can be done if you have a lot of time.
Peter Lugtig
Professor data quality
I am full professor of data quality at Utrecht University, department of Methodology and Statistics.